- Trang chủ
- Giới thiệu
-
Dịch vụ
-
Thiết kế website
-
 Thiết kế website giới thiệu doanh nghiệp
Thiết kế website giới thiệu doanh nghiệp
 Thiết kế website giới thiệu doanh nghiệp
Thiết kế website giới thiệu doanh nghiệp - công ty giúp xây dựng thương hiệu trên Internet hiệu quả, xây dựng chiến lược Marketing để tăng trưởng doanh thu. Mona với hơn 980+ dự án khách hàng và hơn hết là 99% khách hàng hài lòng tuyệt đối. Bạn sẽ sở hữu ngay 1 trang web độc quyền, giao diện đẹp tạo dấu ấn thương hiệu riêng và tính năng theo yêu cầu. Các yếu tố chuẩn SEO, chuẩn di động, UX người dùng, thao tác quản lý dễ dàng luôn là yếu tố được chúng tôi đảm bảo.Giá: từ 7,000,000đ đến 30,000,000đXem thêm
Thiết kế website giới thiệu doanh nghiệp
Thiết kế website giới thiệu doanh nghiệp - công ty giúp xây dựng thương hiệu trên Internet hiệu quả, xây dựng chiến lược Marketing để tăng trưởng doanh thu. Mona với hơn 980+ dự án khách hàng và hơn hết là 99% khách hàng hài lòng tuyệt đối. Bạn sẽ sở hữu ngay 1 trang web độc quyền, giao diện đẹp tạo dấu ấn thương hiệu riêng và tính năng theo yêu cầu. Các yếu tố chuẩn SEO, chuẩn di động, UX người dùng, thao tác quản lý dễ dàng luôn là yếu tố được chúng tôi đảm bảo.Giá: từ 7,000,000đ đến 30,000,000đXem thêm -
 Thiết kế website theo yêu cầu
Thiết kế website theo yêu cầu
 Thiết kế website theo yêu cầu
Một phong cách riêng và những tính năng đặc biệt chỉ riêng website của bạn sở hữu khi đến với dịch vụ thiết kế web theo yêu cầu của Mona Media. Chúng tôi không làm web rẻ tiền, web rác, chúng tôi chỉ nhận thiết kế website cao cấp, mang lại hiệu quả trong hoạt động kinh doanh của khách hàng. Chúng tôi hỗ trợ 24/7 để đáp ứng yêu cầu, feedback của khách hàng nhanh, kịp thời.Giá: từ 7,000,000đ đến 30,000,000đXem thêm
Thiết kế website theo yêu cầu
Một phong cách riêng và những tính năng đặc biệt chỉ riêng website của bạn sở hữu khi đến với dịch vụ thiết kế web theo yêu cầu của Mona Media. Chúng tôi không làm web rẻ tiền, web rác, chúng tôi chỉ nhận thiết kế website cao cấp, mang lại hiệu quả trong hoạt động kinh doanh của khách hàng. Chúng tôi hỗ trợ 24/7 để đáp ứng yêu cầu, feedback của khách hàng nhanh, kịp thời.Giá: từ 7,000,000đ đến 30,000,000đXem thêm -
 Thiết kế website trọn gói
Thiết kế website trọn gói
 Thiết kế website trọn gói
Thiết kế websit trọn gói giải quyết toàn bộ nỗi lo và mong muốn của bạn. Bạn sẽ được tư vấn và xây dựng trang web trọn gói từ: chọn domain, hosting VPS đến xây dựng giao diện, tính năng phù hợp và đặc biệt là được tư vấn, giải quyết vấn đề về Marketing Online với dịch vụ SEO và chiến lược xây dựng content trên website phù hợp, hiệu quả trong lĩnh vực của bạn.Giá: từ 7,000,000đ đến 30,000,000đXem thêm
Thiết kế website trọn gói
Thiết kế websit trọn gói giải quyết toàn bộ nỗi lo và mong muốn của bạn. Bạn sẽ được tư vấn và xây dựng trang web trọn gói từ: chọn domain, hosting VPS đến xây dựng giao diện, tính năng phù hợp và đặc biệt là được tư vấn, giải quyết vấn đề về Marketing Online với dịch vụ SEO và chiến lược xây dựng content trên website phù hợp, hiệu quả trong lĩnh vực của bạn.Giá: từ 7,000,000đ đến 30,000,000đXem thêm -
 Thiết kế website nhập hàng
Thiết kế website nhập hàng
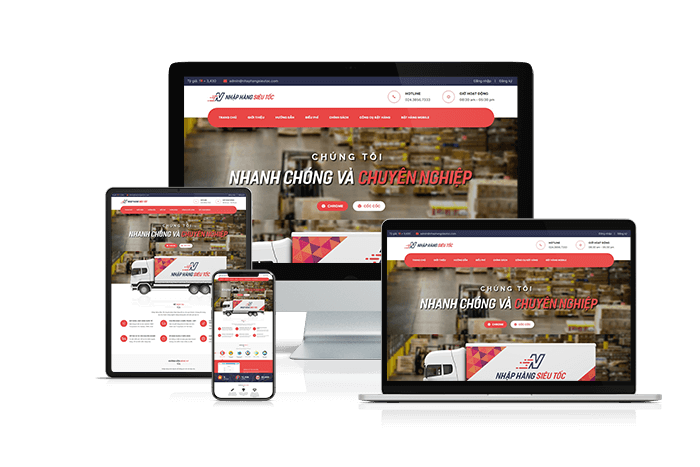 Thiết kế website nhập hàng
Một giải pháp độc quyền và duy nhất có tại Việt Nam về website - phần mềm đặt hàng Trung Quốc, Mỹ và các trang TMĐT Taobao, 1688, Amazon,... Chúng tôi không chỉ thiết kế website nhập hàng mà đi kèm là xây dựng web app quản lý, app điện thoại di động để đáp ứng nhu cầu của người dùng. Hơn 100+ doanh nghiệp đã xây dựng hệ thống của họ trên nền tảng của chúng tôi. Còn bạn thì sao?Giá: từ 7,000,000đ đến 50,000,000đXem thêm
Thiết kế website nhập hàng
Một giải pháp độc quyền và duy nhất có tại Việt Nam về website - phần mềm đặt hàng Trung Quốc, Mỹ và các trang TMĐT Taobao, 1688, Amazon,... Chúng tôi không chỉ thiết kế website nhập hàng mà đi kèm là xây dựng web app quản lý, app điện thoại di động để đáp ứng nhu cầu của người dùng. Hơn 100+ doanh nghiệp đã xây dựng hệ thống của họ trên nền tảng của chúng tôi. Còn bạn thì sao?Giá: từ 7,000,000đ đến 50,000,000đXem thêm -
Thiết kế website bán hàng
 Thiết kế website bán hàng
Xây dựng 1 hệ thống kinh doanh bán hàng hiệu quả, chuyển đổi cao với dịch vụ thiết kế website bán hàng của Mona Media. Một website hoàn toàn chuẩn SEO, chuẩn di động và hơn hết là dễ dàng quản lý, dễ dàng up sản phẩm mới. Chúng tôi đã hỗ trợ tư vấn, định hướng xây dựng giao diện website tối ưu trải nghiệm và tăng tỷ lệ chuyển đổi thành đơn hàng cho hơn 300+ khách hàng.Giá: từ 7,000,000đ đến 30,000,000đXem thêm
Thiết kế website bán hàng
Xây dựng 1 hệ thống kinh doanh bán hàng hiệu quả, chuyển đổi cao với dịch vụ thiết kế website bán hàng của Mona Media. Một website hoàn toàn chuẩn SEO, chuẩn di động và hơn hết là dễ dàng quản lý, dễ dàng up sản phẩm mới. Chúng tôi đã hỗ trợ tư vấn, định hướng xây dựng giao diện website tối ưu trải nghiệm và tăng tỷ lệ chuyển đổi thành đơn hàng cho hơn 300+ khách hàng.Giá: từ 7,000,000đ đến 30,000,000đXem thêm -
 Thiết kế website du lịch
Thiết kế website du lịch
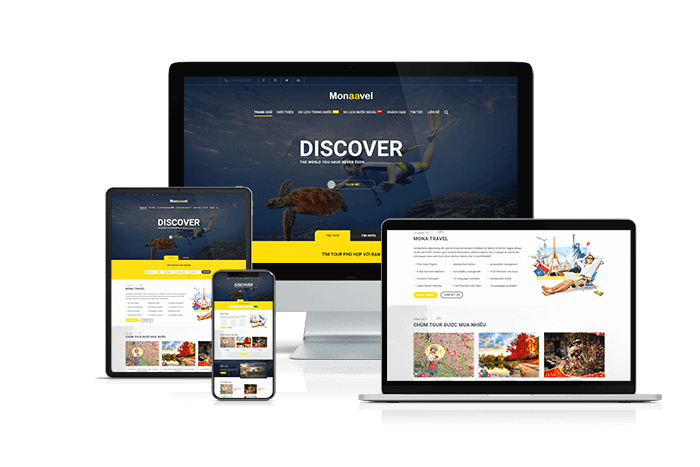 Thiết kế website du lịch
Thiết kế website du lịch ngoài yếu tố giao diện phải đặc biệt đẹp, phong cách, tốc độ load nhanh thì cần phải có hệ thống tính năng booking hoàn hảo, đáp ứng nhanh chóng yêu cầu truy xuất, tìm kiếm của người dùng. Đặc biệt là yếu tố chuẩn SEO, tương thích di động và dễ dàng quản lý, nhập liệu tour... sẽ luôn đảm bảo.Giá: từ 7,000,000đ đến 30,000,000đXem thêm
Thiết kế website du lịch
Thiết kế website du lịch ngoài yếu tố giao diện phải đặc biệt đẹp, phong cách, tốc độ load nhanh thì cần phải có hệ thống tính năng booking hoàn hảo, đáp ứng nhanh chóng yêu cầu truy xuất, tìm kiếm của người dùng. Đặc biệt là yếu tố chuẩn SEO, tương thích di động và dễ dàng quản lý, nhập liệu tour... sẽ luôn đảm bảo.Giá: từ 7,000,000đ đến 30,000,000đXem thêm -
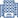 Thiết kế website khách sạn
Thiết kế website khách sạn
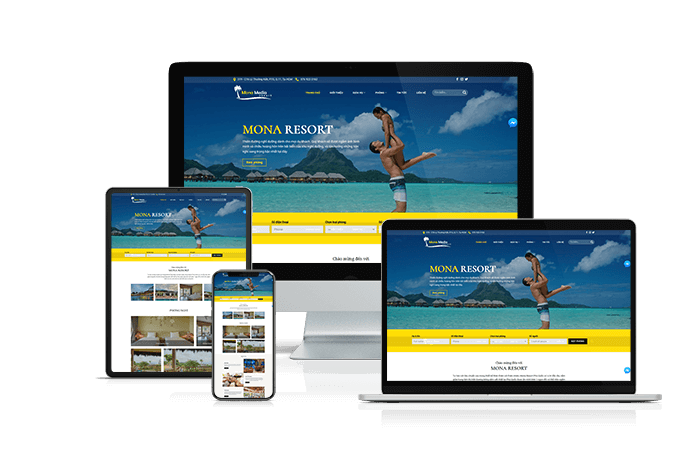 Thiết kế website khách sạn
Bạn cần gì ở 1 website khách sạn? Là 1 website giới thiệu khách sạn thật đẹp, chuẩn 3 - 5 sao hay là 1 trang web với tính năng đặt phòng chuyên nghiệp? Mona Media sẽ giúp bạn tích hợp thành 1 website chuyên nghiệp, giao diện riêng, chuẩn SEO và di động. Tính năng chuyên nghiệp nhưng lại dễ dảng quản lý, dễ dàng thống kê, tích hợp tính năng thanh toán Online, các cổng thanh toán theo yêu cầu khách hàng.Giá: từ 7,000,000đ đến 30,000,000đXem thêm
Thiết kế website khách sạn
Bạn cần gì ở 1 website khách sạn? Là 1 website giới thiệu khách sạn thật đẹp, chuẩn 3 - 5 sao hay là 1 trang web với tính năng đặt phòng chuyên nghiệp? Mona Media sẽ giúp bạn tích hợp thành 1 website chuyên nghiệp, giao diện riêng, chuẩn SEO và di động. Tính năng chuyên nghiệp nhưng lại dễ dảng quản lý, dễ dàng thống kê, tích hợp tính năng thanh toán Online, các cổng thanh toán theo yêu cầu khách hàng.Giá: từ 7,000,000đ đến 30,000,000đXem thêm -
Thiết kế website nhà hàng
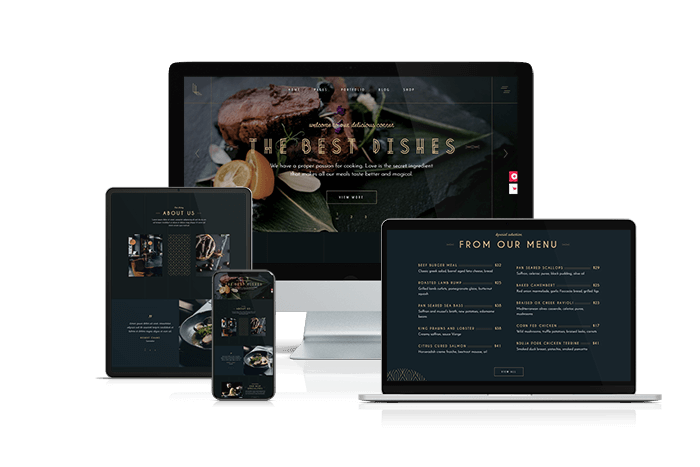 Thiết kế website nhà hàng
Với 450 khách hàng trong 8+ năm qua, dịch vụ thiết kế website của Mona Media tự hào khẳng định chúng tôi đã mang đến tỉ lệ hài lòng tuyệt đối cho khách hàng. Chúng tôi chỉ thực hiện những dự án website được đầu tư từ khách hàng, những website mang lại giá trị, mang lại tầm ảnh hưởng cho doanh nghiệp/công ty, Mona Media không làm website giá rẻ, website mỳ ăn liền, website rác. Chúng tôi tự hào khi đã có phần tham gia đóng góp trực tiếp đến thành công cho các khách hàng.Giá: từ 7,000,000đ đến 30,000,000đXem thêm
Thiết kế website nhà hàng
Với 450 khách hàng trong 8+ năm qua, dịch vụ thiết kế website của Mona Media tự hào khẳng định chúng tôi đã mang đến tỉ lệ hài lòng tuyệt đối cho khách hàng. Chúng tôi chỉ thực hiện những dự án website được đầu tư từ khách hàng, những website mang lại giá trị, mang lại tầm ảnh hưởng cho doanh nghiệp/công ty, Mona Media không làm website giá rẻ, website mỳ ăn liền, website rác. Chúng tôi tự hào khi đã có phần tham gia đóng góp trực tiếp đến thành công cho các khách hàng.Giá: từ 7,000,000đ đến 30,000,000đXem thêm -
Thiết kế website bất động sản
 Thiết kế website bất động sản
Với hơn 200+ dự án thiết kế website cho các công ty bất động sản, nhà môi giới, chủ thầu dự án và cả cá nhân làm BĐS, Mona Media sẽ mang đến cho bạn 1 website giao diện độc quyền, code tính năng riêng, phù hợp với mục đích của từng loại website. Giúp bạn giới thiệu dự án, kinh doanh nhà đất hiệu quả với website chuẩn SEO lên top Google, chuẩn Mobile - hỗ trợ tư vấn gói SEO Bất động sản.Giá: từ 7,000,000đ đến 30,000,000đXem thêm
Thiết kế website bất động sản
Với hơn 200+ dự án thiết kế website cho các công ty bất động sản, nhà môi giới, chủ thầu dự án và cả cá nhân làm BĐS, Mona Media sẽ mang đến cho bạn 1 website giao diện độc quyền, code tính năng riêng, phù hợp với mục đích của từng loại website. Giúp bạn giới thiệu dự án, kinh doanh nhà đất hiệu quả với website chuẩn SEO lên top Google, chuẩn Mobile - hỗ trợ tư vấn gói SEO Bất động sản.Giá: từ 7,000,000đ đến 30,000,000đXem thêm -
 Thiết kế website tin tức
Thiết kế website tin tức
 Thiết kế website tin tức
Thiết kế một website tin tức chuyên nghiệp tại công ty Monamedia là giải pháp tốt nhất để bạn sở hữu một trang web thông tin đầy đủ tính năng. Bạn cần một website tin tức với chức năng quản trị bài đăng đơn giản và dễ sử dụng để cập nhật nhanh chóng, cần tính năng lấy thông tin tự động từ internet để làm phong phú các tin tức trên website hay một trang web chuẩn SEO, được Responsive kỹ lưỡng từng giao diện một, tất cả những gì bạn cần đều sẽ được Mona hỗ trợ trong gói dịch vụ thiết kế web tin tức của chúng tôi.Giá: từ 7,000,000đ đến 30,000,000đXem thêm
Thiết kế website tin tức
Thiết kế một website tin tức chuyên nghiệp tại công ty Monamedia là giải pháp tốt nhất để bạn sở hữu một trang web thông tin đầy đủ tính năng. Bạn cần một website tin tức với chức năng quản trị bài đăng đơn giản và dễ sử dụng để cập nhật nhanh chóng, cần tính năng lấy thông tin tự động từ internet để làm phong phú các tin tức trên website hay một trang web chuẩn SEO, được Responsive kỹ lưỡng từng giao diện một, tất cả những gì bạn cần đều sẽ được Mona hỗ trợ trong gói dịch vụ thiết kế web tin tức của chúng tôi.Giá: từ 7,000,000đ đến 30,000,000đXem thêm -
 Thiết kế website học trực tuyến
Thiết kế website học trực tuyến
 Thiết kế website học trực tuyến
Bạn đang có ý định xây dựng hệ thống học trực tuyến thì không thể bỏ qua dịch vụ thiết kế website Eleanring. Chúng tôi sẽ tư vấn và xây dựng cho bạn 1 website bán khoá học tối ưu nhất cho ngân sách của bạn. Đặc biệt là tính năng chống Download độc quyền bảo vệ trí tuệ và công sức của bạn. Đây là hệ thống duy nhất tại Việt Nam, tích hợp cả tính năng quản lý với Web app, bạn hoàn toàn dễ dang quản lý học viên, doanh thu, bán khoá học, dụng cụ học tập phù hợp cho cả cá nhân và tổ chức muốn bán khoá học.Giá: từ 7,000,000đ đến 30,000,000đXem thêm
Thiết kế website học trực tuyến
Bạn đang có ý định xây dựng hệ thống học trực tuyến thì không thể bỏ qua dịch vụ thiết kế website Eleanring. Chúng tôi sẽ tư vấn và xây dựng cho bạn 1 website bán khoá học tối ưu nhất cho ngân sách của bạn. Đặc biệt là tính năng chống Download độc quyền bảo vệ trí tuệ và công sức của bạn. Đây là hệ thống duy nhất tại Việt Nam, tích hợp cả tính năng quản lý với Web app, bạn hoàn toàn dễ dang quản lý học viên, doanh thu, bán khoá học, dụng cụ học tập phù hợp cho cả cá nhân và tổ chức muốn bán khoá học.Giá: từ 7,000,000đ đến 30,000,000đXem thêm
-
-
Lập trình web-app
-
 Lập trình web app theo yêu cầu
Lập trình web app theo yêu cầu
Thiết kế Web Application theo yêu cầu chuyên nghiệp với Mona. Chúng tôi đã thực hiện hơn 200 dự án về phần mềm và Web app cho các hệ thống - trung tâm lớn, đội ngũ nhân viên tận tình và chuyên nghiệp luôn hỗ trợ cho khách hàng 24/7 và nhận phản hồi để hoàn thiện dự án liên tục cho quý khách hàng.Giá: từ 7,000,000đ đến 30,000,000đXem thêm
Lập trình web app theo yêu cầu
Lập trình web app theo yêu cầu
Thiết kế Web Application theo yêu cầu chuyên nghiệp với Mona. Chúng tôi đã thực hiện hơn 200 dự án về phần mềm và Web app cho các hệ thống - trung tâm lớn, đội ngũ nhân viên tận tình và chuyên nghiệp luôn hỗ trợ cho khách hàng 24/7 và nhận phản hồi để hoàn thiện dự án liên tục cho quý khách hàng.Giá: từ 7,000,000đ đến 30,000,000đXem thêm -
Lập trình web app trọn gói
Lập trình web app trọn gói
Thiết kế web app trọn gói tại Mona sẽ mang lại cho bạn một nền tảng web app hoạt động đa dạng trên nhiều thiết bị, có thể hoạt động được cả online và offline. Ngoài ra, còn giúp cho tiết kiệm được chi phí phần mềm và hạ tầng, Mona luôn là công ty có dịch vụ hỗ trợ khách hàng tận tình hướng dẫn sử dụng và hỗ trợ triển khai cho quý doanh nghiệp.Giá: từ 7,000,000đ đến 30,000,000đXem thêm
-
Web app quản lý trung tâm ngoại ngữ
Web app quản lý trung tâm ngoại ngữ
Với 450 khách hàng trong 8+ năm qua, dịch vụ thiết kế website của Mona Media tự hào khẳng định chúng tôi đã mang đến tỉ lệ hài lòng tuyệt đối cho khách hàng. Chúng tôi chỉ thực hiện những dự án website được đầu tư từ khách hàng, những website mang lại giá trị, mang lại tầm ảnh hưởng cho doanh nghiệp/công ty, Mona Media không làm website giá rẻ, website mỳ ăn liền, website rác. Chúng tôi tự hào khi đã có phần tham gia đóng góp trực tiếp đến thành công cho các khách hàng.Giá: từ 7,000,000đ đến 30,000,000đXem thêm
-
-
Dịch vụ SEO
-
Dịch vụ SEO tổng thể
Dịch vụ SEO tổng thể
Dịch vụ SEO tổng thể là cực kỳ cần thiết và là chiến lược lâu dài giúp website có nền tảng SEO vững chắc - không bao giờ bị phạt vì làm chắc chắn từ đầu. Hiệu quả thể hiện bằng việc toàn bộ keywords chính, phụ và liên quan trong lĩnh vực của bạn lên top Googlle. Lên top Google theo từng bộ từ khoá lớn chứ không chỉ là 1 vài từ khoá với content thu hút, Onpage chi tiết từng trang, backlinks lớn và hệ thống links đa dạng, phù hợp lĩnh vực.Giá: từ 15,000,000đXem thêm
-
Dịch vụ SEO từ khoá
Dịch vụ SEO từ khoá
Dịch vụ SEO tổng thể có thể giúp website lên top hàng nghìn từ khóa liên quan nhưng lại khó có thể tập trung vào lĩnh vực, sản phẩm hay dịch vụ chính của doanh nghiệp. Vì vậy là mà dịch vụ SEO từ khóa theo yêu cầu, giúp công ty có tập trung đẩy mạnh, phát triển những mảng dịch vụ chính của mình, tăng mạnh lượng khách hàng thông qua những từ khóa khó (nhiều lượt tìm kiếm). Dịch vụ SEO từ khóa được triển khai sau khi website đã thực hiện tổng thể và có tín hiệu mạnh trên internet, sự tin tưởng của các công cụ tìm kiếm nhằm mang lại hiệu quả tốt nhất, tránh tình trạng bị phạt bởi thuật toàn của Google, giúp trang web lên top hàng nghìn từ khóa, có lượt truy cập cao nhưng vẫn tập trung vào những từ khóa chính mang lại khách hàng, nguồn thu nhập cao cho doanh nghiệp.Giá: từ 5,000,000đ đến 900,000,000đXem thêm
-
Dịch vụ SEO Hồ Chí Minh
Dịch vụ SEO Hồ Chí Minh
Chỉ sau khoảng 2 năm thương mại hóa dịch vụ SEO, Monamedia đã thực hiện thành công cho nhiều khách hàng muốn triển khai SEO tại HCM, các dự án mà chúng tôi đã triển khai SEO thành công như hungphuckhang.com, phuctruonghai.vn, maas.vn,... và hiện Mona đang triển khai nhiều dự án khác, khách hàng chủ yếu là các chủ doanh nghiệp, công ty đang kinh doanh và có nhu cầu muốn tìm kiếm, hợp tác cùng các dịch vụ SEO uy tín tại HCM. Nếu bạn đang cần một agency tại HCM triển khai SEO website thì hãy liên hệ ngay với chúng tôi qua hotline 1900 636 648.Giá: từ 50,000,000đXem thêm
-
-
Lập trình phần mềm
-
Phần mềm quản lý tour du lịch
Phần mềm quản lý tour du lịch
Thiết kế phần mềm quản lý tour du lịch mang đến cho quý doanh nghiệp quá trình điều hành và quản lý cực kỳ đơn giản mà lại không quá phức tạp. Với phần mềm quản lý tour bạn dễ dàng theo dõi được lịch trình của từng tour, đoàn du lịch trên thiết bị phần mềm, từ đó doanh thu cũng sẽ tăng lên. Muốn hay không là quyết định ở bạn, Mona ở đây để giúp bạn thực hiện điều đó.Giá: từ 30,000,000đXem thêm
-
Phần mềm quản lý kho - bãi
Phần mềm quản lý kho - bãi
Vấn đề tồn kho? Vấn đề vận tải? Không còn là nổi lo đến quý doanh nghiệp. Chúng tôi là Mona chuyên thiết kế phần mềm quản lý, trong đó phần mềm quản lý vận tải, quản lý kho luôn được khách hàng tin dùng tuyệt đối. Với hơn 8+ năm làm nghề và phục vụ cho hơn 300+ quý doanh nghiệp, khách hàng thì Mona chính là sự lựa chọn dành cho bạn.Giá: từ 30,000,000đXem thêm
-
 Phần mềm hóa đơn điện tử
Phần mềm hóa đơn điện tử
Những hóa đơn bằng giấy giờ đây đã có thể thay đổi được bằng phần mềm điện tử, phần mềm công nghệ. Với việc thiết kế phần mềm hóa đơn điện tử cho phép bạn dễ dàng lưu trữ và tính toán đến độ chính xác tuyệt đối, giúp cho việc quản lý nhanh chóng tiết kiệm thời gian. Mona đã thiết kế phần mềm hóa đơn điện tử cho hơn 300+ doanh nghiệp và luôn là một trong những sự lựa chọn tốt nhất của mọi người.Giá: từ 30,000,000đXem thêm
Phần mềm hóa đơn điện tử
Phần mềm hóa đơn điện tử
Những hóa đơn bằng giấy giờ đây đã có thể thay đổi được bằng phần mềm điện tử, phần mềm công nghệ. Với việc thiết kế phần mềm hóa đơn điện tử cho phép bạn dễ dàng lưu trữ và tính toán đến độ chính xác tuyệt đối, giúp cho việc quản lý nhanh chóng tiết kiệm thời gian. Mona đã thiết kế phần mềm hóa đơn điện tử cho hơn 300+ doanh nghiệp và luôn là một trong những sự lựa chọn tốt nhất của mọi người.Giá: từ 30,000,000đXem thêm -
Phần mềm quản lý bán hàng
 Phần mềm quản lý bán hàng
Chưa bao giờ quản lý dễ dàng đến thế, bài toán bán hàng được giải quyết nhanh chóng và tiện lợi chỉ với phần mềm quản lý bán hàng. Không chỉ thế mà lợi ích từ phần mềm bán hàng máy POS mang lại nhiều hơn những gì bạn đang nghĩ, với sự phát triển và cạnh tranh từng ngày như hiện nay thì quản lý bằng tay không thể nào cạnh tranh nổi.Giá: từ 30,000,000đXem thêm
Phần mềm quản lý bán hàng
Chưa bao giờ quản lý dễ dàng đến thế, bài toán bán hàng được giải quyết nhanh chóng và tiện lợi chỉ với phần mềm quản lý bán hàng. Không chỉ thế mà lợi ích từ phần mềm bán hàng máy POS mang lại nhiều hơn những gì bạn đang nghĩ, với sự phát triển và cạnh tranh từng ngày như hiện nay thì quản lý bằng tay không thể nào cạnh tranh nổi.Giá: từ 30,000,000đXem thêm -
Phần mềm quản lý doanh nghiệp
Phần mềm quản lý doanh nghiệp
Phần mềm quản lý doanh nghiệp hay còn gọi là phần mềm ERP mang đến lợi ích vượt trội so với đối thủ, nâng cao khả năng cạnh tranh dựa trên sự quản lý chuyên nghiệp và giám sát liên tục. Với phần mềm ERP bạn có thể quản lý từ xa mà không cần phải gặp trực tiếp, dễ dàng tương thích trên mọi thiết bị.Giá: từ 30,000,000đXem thêm
-
 Phần mềm quản lý khách hàng
Phần mềm quản lý khách hàng
Quản lý khách hàng, chăm sóc khách hàng chính là lợi thế mà mỗi doanh nghiệp muốn có để mong muốn khách hàng đến với doanh nghiệp của mình hơn. Giờ đây bạn dễ dàng làm điều đó với thiết kế phần mềm quản lý khách hàng được thực hiện bởi Mona, chúng tôi đã thực hiện hơn 980+ dự án và có nhiều năm trong lĩnh vực phần mềm và luôn được khách hàng đánh giá tốt về sự chuyên nghiệp.Giá: từ 30,000,000đXem thêm
Phần mềm quản lý khách hàng
Phần mềm quản lý khách hàng
Quản lý khách hàng, chăm sóc khách hàng chính là lợi thế mà mỗi doanh nghiệp muốn có để mong muốn khách hàng đến với doanh nghiệp của mình hơn. Giờ đây bạn dễ dàng làm điều đó với thiết kế phần mềm quản lý khách hàng được thực hiện bởi Mona, chúng tôi đã thực hiện hơn 980+ dự án và có nhiều năm trong lĩnh vực phần mềm và luôn được khách hàng đánh giá tốt về sự chuyên nghiệp.Giá: từ 30,000,000đXem thêm
-
-
Lập trình ứng dụng di động
-
Ứng dụng bán hàng
Lập trình ứng dụng bán hàng
Thiết kế ứng dụng bán hàng là một trong những thế mạnh của Monamedia, chúng tôi xây dựng các app bán hàng dựa trên nền tảng website, giúp ứng dụng hoạt động mượt mà và quan trọng hơn là sẽ đồng bộ rất nhanh với website, giúp khách hàng có thể dễ dàng quản lý hiệu quả bán hàng trên cả web và app dễ dàng. Ứng dụng có thể hoạt động trên đa thiết bị, đa nền tảng, từ iOS cho đến Android, giúp doanh nghiệp tiếp cận mọi khách hàng.Giá: từ 7,000,000đXem thêm
-
Ứng dụng quản lý nhà trọ
Ứng dụng quản lý nhà trọ
Phần mềm quản lý nhà trọ - phòng trọ MonaHouse được viết và sở hữu độc quyền bởi công ty Monamedia, mang đến giải pháp quản lý hiệu quả cho chủ kinh doanh phòng trọ hoặc các dịch vụ cho thuê bất động sản khác. Bộ ứng dụng cực kỳ dễ sử dụng, chỉ cần cài đặt và thiết lập các thông tin cơ bản là có thể sử dụng, với mức chi phí thấp chỉ tối thiểu 6000đ/ngày nhưng phần mềm vẫn được tối ưu kỹ để phù hợp với từng người sử dụng cũng như từng mô hình kinh doanh khác nhau.Giá: từ 160,000đ/thángXem thêm
-
Ứng dụng học trực tuyến
Ứng dụng học trực tuyến
Monamedia đã thiết kế nhiều phần mềm học trực tuyến, giải pháp elearning cho nhiều tổ chức giáo dục hiện nay, giải pháp học online bao gồm việc quản trị các video, tài liệu khóa học cho đến quản lý các giảng viên, học viên tham gia các khóa học online trên website hay ứng dụng học trực tuyến. Ngoài ra hệ thống cũng cho phép tạo các bài kiểm tra online để đánh giá chất lượng đào tạo cũng như trình độ học viên trước và sau khi đào tạo như thế nào, hệ thống trắc nghiệm hoàn toàn tự động và chỉ cần nhập câu hỏi một lần, thứ tự câu hỏi và đáp án sẽ tự động thay đổi ngẫu nhiên mỗi khi học viên vào thực hiện kiểm tra.Giá: từ 15,000,000đXem thêm
-
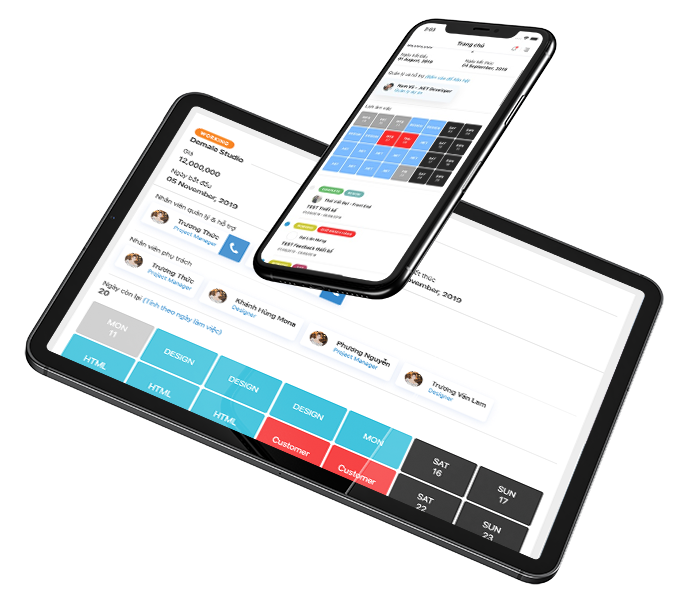
Ứng dụng quản lý dự án
Ứng dụng quản lý dự án
Phần mềm quản lý dự án - theo dõi tiến độ công việc của Mona là giải pháp cho các doanh nghiệp muốn triển khai các phần mềm quản lý project của mình. Hiện tại thì phần mềm này đang được chính chúng tôi sử dụng để quản lý dự án của công ty, với một công ty dịch vụ như Mona thì quản lý sự án cực kỳ phức tạp và quan trọng. Ứng dụn PMS được thiết kế để khách hàng của thể tham gia vào theo dõi dự án của mình, cập nhật nhanh tiến độ cũng như thời gian hoàn thành giúp khách hàng yên tâm, nhân viên cũng dễ dàng quản lý công việc được phân công từ cấp trên.Giá: từ 7,000,000đ đến 30,000,000đXem thêm
-
-
Thiết kế website
- Dự án
- Mẫu website
- Blog
- Liên hệ